Job Pipeline
What is the job?
A Job is a script that can execute a Data App with full parameters to create and update data for a single table. All Chainslake jobs are organized in the jobs folder of the data-builder repository.
Example: cex/binance/trade_minute
$CHAINSLAKE_HOME_DIR/spark/script/chainslake-run.sh --class chainslake.cex.Main \
--name BinanceTradeMinute \
--master local[4] \
--driver-memory 4g \
--conf "spark.app_properties.app_name=binance_cex.trade_minute" \
--conf "spark.app_properties.binance_cex_url=$BINANCE_CEX_URL" \
--conf "spark.app_properties.number_re_partitions=4" \
--conf "spark.app_properties.quote_asset=USDT" \
--conf "spark.app_properties.wait_milliseconds=1" \
--conf "spark.app_properties.config_file=binance/application.properties"
Job configuration
- –class: config Main of App’s package
- –name: Name of job
- –master: Config number of core used to run job
- –driver-memory: Config the amount of RAM allocated to the job
- –conf “spark.app_properties.app_name=”: Configure the name of the app that the job will execute
- –conf “spark.app_properties.config_file=”: Config the job configuration file path.
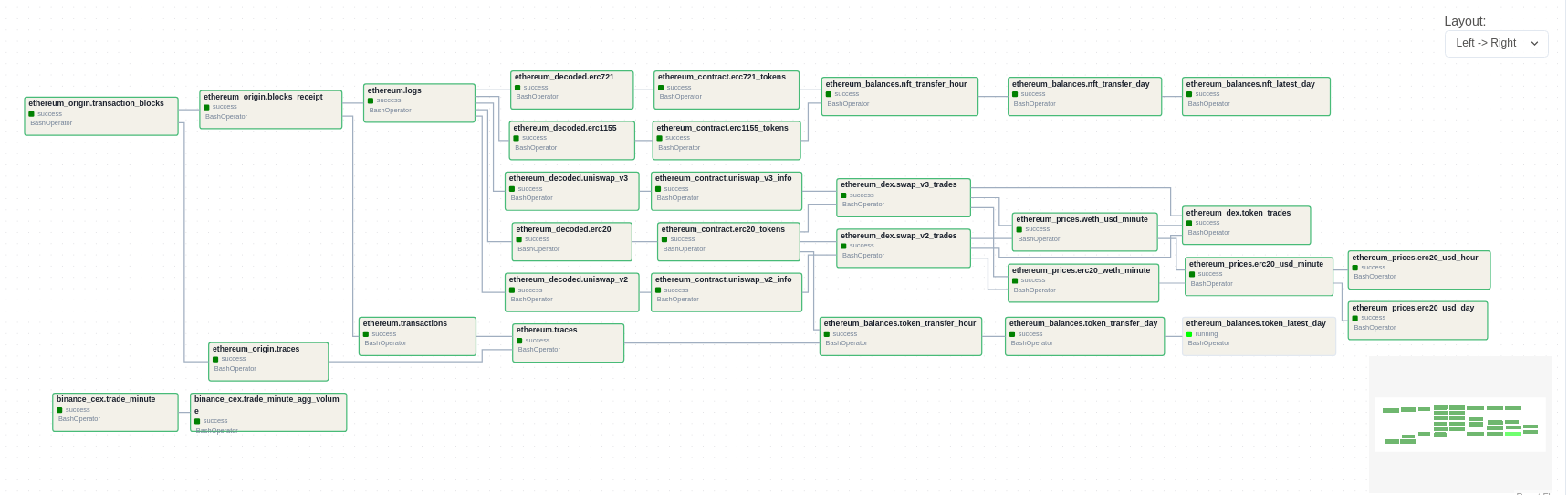
What is the pipeline?
Pipeline is a directed graph that connects jobs in the order they are executed. Chainslake uses Airflow to automate and execute jobs in a DAG, ensuring that jobs are always executed in the correct order, with a controlled number of concurrent jobs.
You can find the entire Chainslake pipeline in the airflow/dags directory in the data-builder project
How to build and submit job and pipeline?
Like Data App, you need to use data-builder to build and submit your work.
- You need to folk data-builder project to your account on github
- Code and test your app on your local
- Commit and push your work to your repository
- Create Pull request to merge your work to main branch of data-builder